.png)

When we are trying to determine which model best fits our demand ,we use the indicator called mean absolute percentage error (MAPE) to analyze the accuracy.
To calculate MAPE we take the data points that we not used to build the forecast equation and we calculate the forecast for those dates accordingly to the equation that we developed.
1.Purple data series is actual demand kept in reserve.
2.Light blue shows what our equation would have forecasted for those dates.
3.It is comparing actual vs forecasted values for our data points. This shows how accurate our forecast model actually is likely to be.
4.MAPE is expressed as a percentage – the lower the value is, the more accurate our forecast. Usually, a MAPE of 15 or less is pretty solid.
In our example we will have a much higher MAPE as our data is just dummy contoso data and doesn’t really express reality.

1.When generating our forecast we need to determine what forecast dimension we are going to include.
1.Mandatory dimensions are company site and allocation key.
2.If we want to be more detailed, we can add additional dimension such as … product and dimensions (which references product dimensions size color style and config)
Let’s address quickly “Granularity attributes” on the impacts on the demand forecast. Lets say you want to run forecasts by company site, allocation key, country/region customer group and item and dimension The values I am getting back, are unique values based a unique combination of the forecast dimension values that I enabled above. (such are also known as granularity attribute) How deep to go here from a granularity aspect is depending on the use case. So different combinations will have different outputs.

Parameters in the system that impact how forecast equation is calculated. The above shows a list of Parameters that we can set in D365FO that will then be used by Azure and R to create the forecast model. Let's take a look at each of those.

This parameter, determines which statistical model is used to calculate the forecast equation. ARIMA stands for Autoregressive integrated moving average. ETS also called Exponential smoothing – with this method we consider our more recent demand history with heavier consideration when we build our formula. Short, While exponential smoothing models are based on a description of the trend and seasonality in the data, ARIMA models aim to describe the autocorrelations in the data. STL: decomposition means that we initially separate out seasonality tend and error in our dataset and add them back together at the end. STL is very well used when there is a lot of data missing in demand history. ETS + ARIMA – Combines ETS and ARIMA. ETS+ STL – Combines ETS and STL. ALL – directs the system to run through all the options and pick the model that gets created with the lowest MAPE value. (most accuracy)
If you don’t have a data scientist in your rows, you probably start with ALL and analyze forecast outputs and evaluate what model was chosen. Please note that if you run it with All it will take more time during forecast generation as its running through all option. You can see in the demand forecast details under model details what model was actually chosen in the end.

Min and max forecasted value. Here I can specify what the limits are on the value of my forecast. I may set my min at 0 or 3. Lets say I want a max of 24. we noticed that the forecast would have give us a 25 back, what is above our max allowed value. Instead our forecast will now show 24 for that data point.

This parameter relates to what happens when we have gaps in historical data, when we don’t have data for a certain time in our history, we need to decide what to do with the gap. This is answered by the missing value substitution parameter. We can specify a number, we can use the average of the previous and following data points, we can just take the previous value or we could do a linear or polynominal interpolation to guess at what that number would have been. In most cases you probably just want to use 0 because we were missing data it is likely that there was no data/demand for that specific date in the past.
We also need to decide the scope of the missing value substitution choice that we just made. We can apply it for our whole history, for the date range of our forecast run or just for a specific granularity attribute. It is recommended to use the global setting here – which applies to substitution of all missing data.

Next we have the confidence level parameter – a confidence interval references the range of possible values that we think the demand might fall in – See the shaded blue region. Purple line represents the forecast. If my confidence level is 95, then the shaded region will show the range which contains the actual future demand value with 95% probability or confidence. The bigger the number of our confidence level, the large the blue shaded area will be. The parameter ranges from 1 to 99 percent in most use cases. It’s not impacting the forecast demand amount itself more how you view the outputs of the forecast generation after the fact.
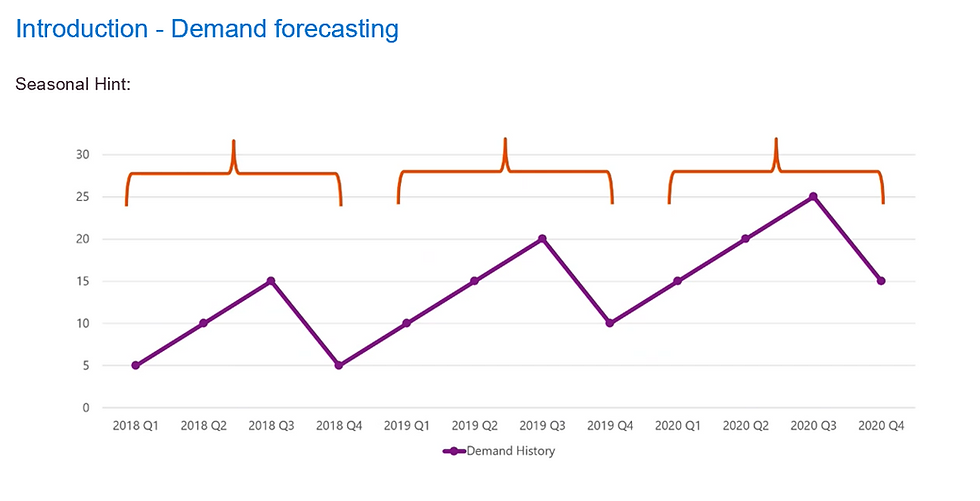
Seasonality can be one component of the forecast. See that there may be a seasonal pattern.The seasonality hint parameter allows us to tell the system on what interval we think our seasonality pattern repeats. E.g. if we have a quarterly seasonality pattern and we are forecasting in monthly buckets, we would put the value 3 in our seasonality hint field.

When we do have models that use seasonality we have the option to specify what the relationship between trend and seasonality is. One option is to define the relationship as additive. What this implies is that our seasonality impact is independent of our trend. We see this represented in the chart where the seasonality pattern remains the same pattern and magnitude remains the same despite the fact that we are overall trending upwards. Another option is to define the relationship is multiplicative. This implies that seasonality and the magnitude of seasonality is dependent on our trend. As our trend goes up here, so does the magnitude of the seasonality – see the graph. We also have the choice to specify none or auto – if we don’t know which one to choose we should select auto and let the system identify the right/more accurate option.

Test size percentage: this allows us to define the amount of data set aside for testing accuracy of the forecast vs. how much should be used to generate the forecast equation. E.g. if we set it to 20%, 20% of historical data we will use to calculate our mean absolute percentage error (MAPE). The remaining 80% would be used to generate the forecast equation. 20% is a good value to start with usually – it is enough data to get a good MAPE measurement usually.
*Pictures are from Microsoft (Source)
Comments